Protokół HTTP
Artykuł dodany: 17 października 2007. Ostatnia modyfikacja: 23 września 2012.
Stopień trudności (1 - dla początkujących, 5 - dla ekspertów): 1
Protokół HTTP jest protokołem warstwy aplikacji, stosowanym do transportu danych w sieci WWW. Pierwsza wersja (HTTP/0.9) została opublikowana pod koniec 1990 roku. Jej pomysłodawcą jest Tim Berners-Lee, założyciel W3C. Zainteresowanych odsyłam na strony w3.org gdzie można zobaczyć szkic owego projektu.
Zrozumienie zasady działania protokołu HTTP jest ogromnie ważne i powinno być pierwszym krokiem na ścieżce nauki dla przyszłych programistów webowych. Sam protokół jest wyjątkowo prosty i polega na wymianie informacji pomiędzy klientem (np. przeglądarką) a serwerem. Klient chcąc otrzymać zasób z serwera wysyła komunikat żądania, w którym określa metodę żądania, identyfikator URI, identyfikator wersji protokołu oraz informacje specyficzne dla danego zasobu. Brzmi skomplikowanie a w rzeczywistości jest bardzo proste i co ważniejsze szybkie. Przykład żądania wysyłanego do serwera możesz zobaczyć na poniższym listingu:
1: GET /index.html HTTP/1.1 2: Host: wwwgo.pl 3: User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1 4: Accept-Encoding: gzip,deflate 5: Connection: Keep-Alive
Transakcja HTTP składa się z listy nagłówków które wysyła przeglądarka / dowolny klient (np. skrypt w PHP lub innym języku) kontaktując się z serwerem. Wysyłanych informacji może być więcej – dla uproszczenia wybrałem tylko kilka z nich. Co one w skrócie oznaczają?
GET – metoda żądania (przykładowo, dla formularzy może być POST)
/index.html – żądamy pliku index.html (dla katalogu głównego będzie to / )
HTTP/1.1 – protokół i jego wersjaHost: xxx – host do którego wysyłamy żądanie
User-Agent – informacje o kliencie, który wysłał żądanie
Accept-Encoding – akceptowany sposób kodowania zawartości
Connection: Keep-Alive – w wersji protokołu HTTP/1.1 wprowadzono możliwość przetwarzania kilku transakcji na jednym, ciągle otwartym połączeniu
Serwer, po otrzymaniu zapytania, analizuje do jakiego hosta jest kierowane, jaki adres klient stara się wczytać, następnie pozostałe nagłówki i udziela odpowiedzi:
1: HTTP/1.1 200 OK 2: Content-Type: application/xhtml+xml;charset=UTF-8 3: Content-Encoding: gzip 4: Server: Apache
HTTP/1.1 – ponownie wersja protokołu. W ten sposób serwer i klient są w stanie uzgodnić najnowszą, wspólną wersję protokołu. Co jeżeli w odpowiedzi otrzymalibyśmy np. HTTP/1.0? Wtedy nastąpiłaby konwersja do najniższej, wspólnie obsługiwanej wersji lub pojawiłby się komunikat błędu i żądanie nie mogłoby być zrealizowane.
200 – kod statusu (status code). Pojawia się zawsze, niezależnie od tego czy żądanie zostało zrealizowane pomyślnie, czy też nie. Kody stanu podzielone są na klasy. Kod stanu można rozszerzyć o własne definicje, a jeżeli klient nie jest w stanie ich zrozumieć, zwracany jest ogólny kod danej klasy. Przykładowo serwer wysyła kod 450, klient go nie zna więc zwraca kod 400.
OK – żądanie zostało poprawnie przetworzone.Content-Type – typ MIME (MIME Media Type) oraz informacja o kodowaniu zawartości
Content-Encoding: gzip – przesyłane w odpowiedzi dane są skompresowane (gzip)
Server – informacje o serwerze
Jak widać klient i serwer “rozmawiają” ze sobą w dość prostym i zrozumiałym także dla człowieka języku. Każdy z nich otrzymuje niezbędne do dalszego działania dane, które przetwarza na swój sposób generując ostatecznie wynik nawet, jeżeli podczas tej rozmowy pojawił się błąd.
Przykład rzeczywistego żądania odczytany w narzędziu Firebug:
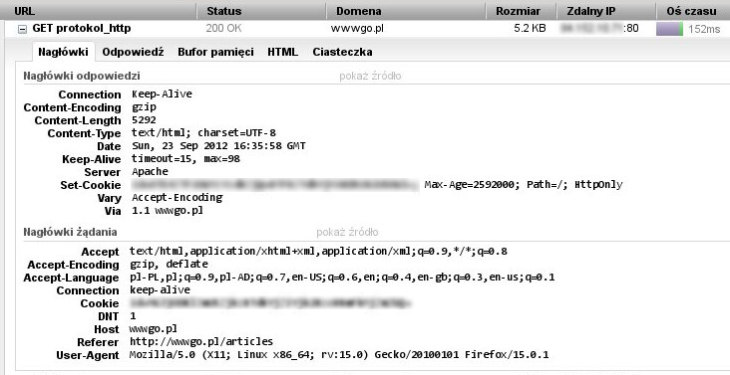
Z powyższego wynika jedna bardzo ważna nota. Nagłówki muszą być wysłane w pierwszej kolejności, jeszcze przed jakąkolwiek inną zawartością ponieważ niosą w sobie informacje niezbędne do dalszego przetworzenia dokumentu. Czy klient musi zdekompresować otrzymaną zawartość, jaka jest długość całkowita dokumentu, czy wreszcie jak potraktować otrzymany ciąg bajtów – w praktyce klient nie wie że ciąg zerojedynkowy to strona html, plik dźwiękowy lub dokument pdf – ustala to na podstawie otrzymanego w odpowiedzi typu MIME.
Bardzo często ludzie pracujący z PHP otrzymują komunikat o wysłanych już nagłówkach (headers already sent). Aby temu zapobiec należy przeprojektować aplikację aby w pierwszej kolejności ustawić nagłówki a dopiero po nich wysłać treść (użyj buforowania, postaraj się zbierać wszystkie nagłówki – wyślij je dopiero gdy wygenerujesz wewnętrznie wszystkie dane i wiesz że nie wystąpi już żaden błąd). Sprawdź również czy na początku dokumentu nie wstawiłeś spacji, lub że edytor nie zapisuje znaku BOM.
Kody statusu
Kody statusu pogrupowane są w klasy wedle pełnionego zadania. I tak:
1xx – kody informacyjne
2xx – kody powodzenia
3xx – kody przekierowania
4xx – kody błędu u klienta
5xx – kody błędu serwera
Pewnie wiele razy zetknąłeś się Czytelniku z komunikatem “404 – Not Found”. Nielubiana informacja ale zarazem bardzo ważna, pozwalająca na ustalenie że poszukiwanego dokumentu po prostu nie ma a nie, że przykładowo został przeniesiony (kod 301). Każda z grup informuje nas dość dokładnie jaki był wynik naszego żądania. Dokładny opis wszystkich kodów dla protokołu HTTP/1.1 można odnaleźć w specyfikacji RFC2616. Kilka przykładowych, najczęściej przesyłanych kodów:
200 – OK – żądanie pomyślnie zrealizowane
206 – Partial Content – serwer zrealizował część zapytania
301 – Moved Permanently – żądany zasób został przeniesiony na nowy adres
302 – Found – żądany zasób jest chwilowo dostępny pod innym adresem
403 – Forbidden – zasób został odnaleziony ale nie masz do niego dostępu
404 – Not Found – szukany zasób nie został odnaleziony
500 – Internal Server Error – błąd serwera który uniemożliwia wykonanie żądania
503 – Service Unavailable – serwer nie może chwilowo zrealizować żądania z powodu przeciążenia lub konserwacji
Podsumowanie
Na zakończenie małe ćwiczenie. Jeżeli pracujesz pod Windows (pod Linuksem otwórz konsolę) uruchom wiersz polecenia (skrót klawiszy win+r, następnie polecenie cmd) i wpisz:
telnet google.com 80 {enter}Telnet to niewielki program umożliwiający komunikację pomiędzy klientem a serwerem. Informujesz, że chcesz połączyć się z serwerem google.com na porcie 80 czyli standardowym porcie HTTP. Powinno pojawić się czyste okno. Przepisz teraz pierwszą linię z wymienionego na początku artykułu żądania klienta (pod Windowsem musisz pisać na “ślepo”, tekst jest wpisywany ale nie będzie się pojawiał):
GET / HTTP/1.1 {enter}{enter}Niezależnie od odpowiedzi jaką dostałeś (ja otrzymuję informację z kodem 302) wykonałeś pracę, jaką na codzień zupełnie przezroczyście wykonuje przeglądarka internetowa gdy odwiedzasz stronę www. Ot, cała filozofia.
Dodaj komentarz
- php
- zend framework
- html
- kodowanie
- mysql
- xml
- xhtml
- postgresql
- css
- programowanie
- bazy danych
- jquery
- javascript
- http
- sieć
- internet
- apache
- zend framework 3
- phptal
- sqlite
Komentarze
Nie ma jeszcze żadnych komentarzy do wyświetlenia. Może chcesz zostać pierwszą osobą która podzieli się swoją opinią?